The effect of Open Data on cost savings
E. Delugas 
Literature background
Measuring the economic impact of open science and open data has proven to be challenging. Many theoretical studies highlight the benefits of making research results public, with strong support for Open Science from economic research on technological change Mazzucato (2011). However, only few studies have attempted to measure the impacts of open science compared to closed science, and more robust evidence on how Open Science drives innovation and economic outcomes is needed to strengthen support and counter emerging criticisms Ali-Khan et al. (2018). The existing literature mainly concentrates on specific sectors, particularly health, medicine, and biosciences, which receive more attention due to early regulation by funders and significant interest in clinical trial outcomes. Another important stream of literature is focused on highlighting the economic value of Open Science through personal industry experiences, though lacking precise quantitative evidence, with contributions from McManamay and Utz (2014) on fisheries, Harding (2017) on medicine, Chan (2015) on the transition to an Open Science model, and Chen, Chen, and Chen (2017) on the role of open data in AI and machine learning applications. Although directly linking economic outcomes to open data initiatives can be challenging, with authors combining theoretical arguments and the limited quantitative evidence available at the time of their publication Arzberger et al. (2004), open access to findings and data is considered to lead to significant savings in access costs. By removing paywalls and subscription fees, open data allows researchers and businesses to access valuable information without incurring additional costs. A major economic benefit of lowering the cost of knowledge is the availability of an extra budget that can be reallocated for other purposes (Tennant et al. 2016).
By eliminating barriers to data access, organisations can reduce the time spent on data collection and focus on core activities. Fell (2019) notes that open science reduces the time associated with accessing new knowledge, directly contributing to enhanced research quality and productivity increases. Although the specific time savings associated with open access were not directly tested, Parsons, Willis, and Holland (2011) conducted an interview-based study that supports this potential benefit. (Neil Beagrie and Houghton 2014) demonstrate that data sharing and curation significantly enhance research efficiency, with labour cost savings ranging from two to over twenty times the operational costs of the data centres. While there are indirect costs associated with preparing data for sharing, such as time and expenses incurred by depositors, the benefits realised by users through improved efficiency and their willingness to pay for access far outweigh these costs (N. Beagrie and Houghton 2012). Additionally, findings from Neil Beagrie and Houghton (2021) provide compelling evidence of the timesaving and efficiency gains associated with using European Bioinformatics Institute services (EMBL-EBI).
Open data minimises redundant data collection and mitigates the “file drawer effect,” where valuable findings remain unpublished and inaccessible, ultimately impeding research effectiveness (Assen et al. 2014). According to (Europe 2019), making research data openly available can save up to 9% of a project’s costs by preventing unnecessary data collection and facilitating the efficient reuse of existing data. Additionally, Houghton, Swan, and Brown (2011) estimate that access barriers to academic research in Denmark cost DKK 540 million annually. This figure is based on the average time spent (51-63 minutes) attempting to access research articles and the study highlights that delays in accessing academic research can prolong product and process development by an average of 2.2 years, resulting in significant financial losses for firms.
The broader implications of open data extend beyond mere cost and time savings. Scientific literature is widely recognised as an important source of strategic knowledge, facilitating the exploration of new ideas in industrial research and innovation, particularly for small and medium enterprises that may struggle to obtain data independently (Publications Office of the European Union, Huyer, and Knippenberg 2020). However, inefficiencies in traditional publishing models, such as delays and biases in data dissemination, can negatively impact private research productivity, as discussed by Harding (2017). Open data benefits various sectors, including agriculture, the environment, forensics, and industrial biotechnology, by providing access to information that helps researchers understand their fields and build on existing work Yozwiak, Schaffner, and Sabeti (2015).
To fully harness the potential of open data, it is important to develop the necessary skills and capacities to manage it effectively. Zeleti and Ojo (2014) emphasise the need to streamline data generation processes to produce insights that inform and shape business strategies. Given that open data initiatives contribute to greater transparency and accountability, businesses that leverage open data achieve cost savings by co-creating and integrating data from multiple sources to enhance their services Lindman, Kinnari, and Rossi (2014). Fell (2019) suggests that adopting an open approach fosters connections and encourages collaborations that might not occur or would take longer in a closed environment. This is exemplified by the work of (Vlijmen et al. 2020), who show how the integration of diverse types of open data, specifically scientific, clinical, and experimental public evidence, can be achieved using advanced AI platforms like Euretos. By combining these various data sources, the platform enhances the depth of information available for analysis, enabling more accurate predictions regarding drug efficacy, as demonstrated by a machine learning model that improved prediction accuracy by 12 percentage points over previous state-of-the-art.
Despite the theoretical benefits of open data, several limitations hinder a comprehensive assessment of its economic impact fully. Implementing open data practices requires significant investments in infrastructure, technology, and training, potentially offsetting some cost savings (Vlijmen et al. 2020). Moreover, the European Commission study emphasises that the benefits of open data are contingent on the quality and standardisation of the data provided (European Commission. Directorate General for Research and Innovation. and PwC EU Services. 2018). Finally, a major limitation is the scarcity of empirical evidence; few studies have attempted to measure the impacts of open science compared to closed science, making it challenging to generalise findings (Karasz et al. 2024). Herala et al. (2016) review the benefits and challenges of open data initiatives in the private sector, highlighting advantages like enhanced collaboration and innovation, but caution that these are often based on speculative assumptions rather than empirical evidence, emphasising the need for further research to inform best practices and mitigate risks associated with increased costs and data privacy concerns.
Directed Acyclic Graph (DAG)
As discussed in the general introduction on causal inference, we use DAGs to represent structural causal models. In the following, a DAG (Figure 1) is employed to examine the causal relationship between Open Data and Cost Savings. The visual illustrates multiple potential pathways, including a direct path from Open Data and Cost Savings, an indirect one involving Time Savings (i.e., a mediator), and additional paths that incorporate factors affecting either Open Data or Time Savings (i.e., confounders). These additional factors, such as technological infrastructure, data quality and availability, standardisation, user skills, innovation, and collaboration introduce layers of complexity to the model. As we will show in the subsequent sections, they are essential to discuss the causal and non-causal, open and closed, relationships among all these variables.
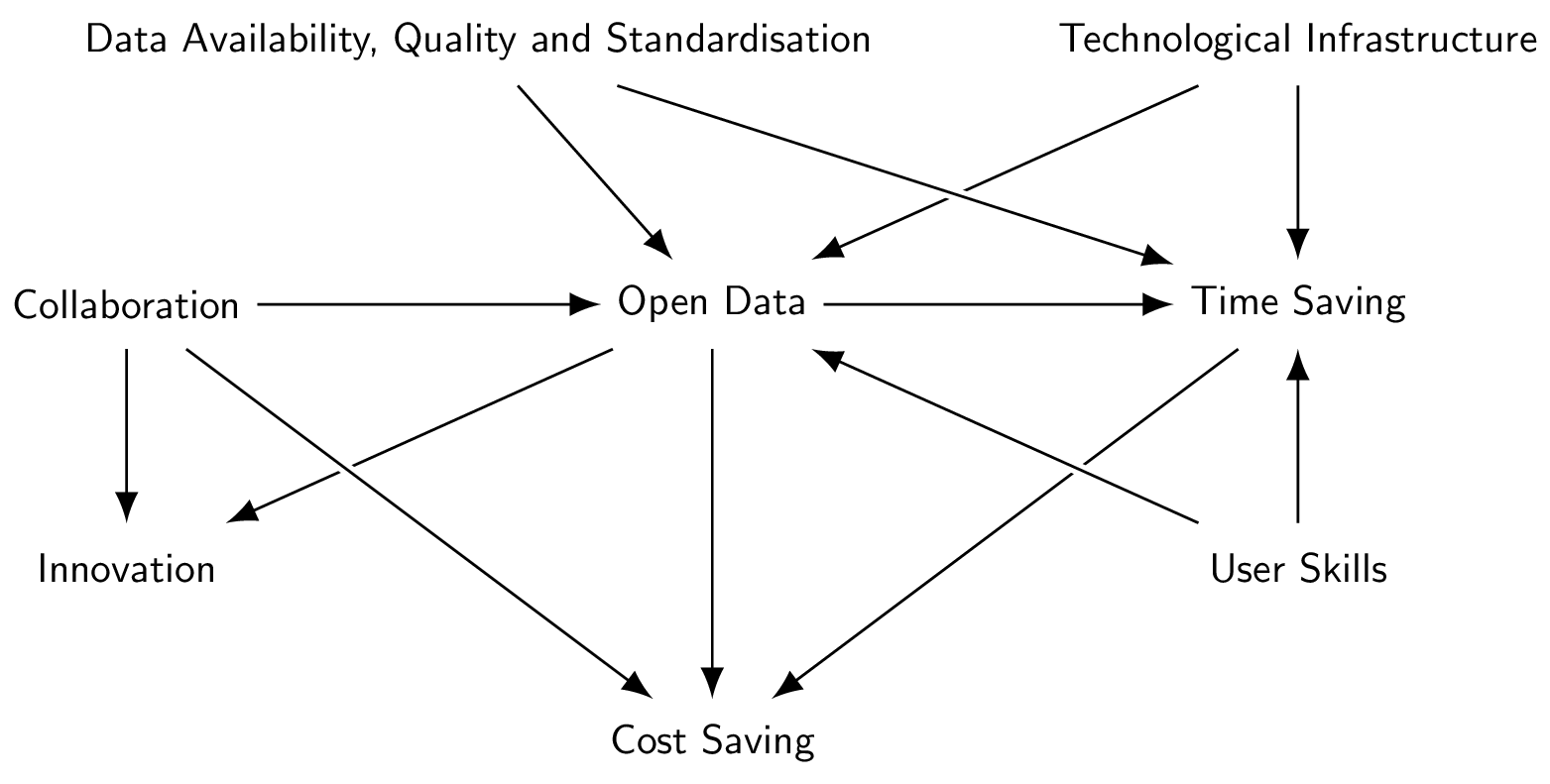
The effect of Open data on Cost Saving
In this section, we apply the concepts presented in the section Causality in Science Studies to potential research questions. We present a specific perspective on causal inference through the lens of structural causal models (Pearl 2009).
Suppose we are interested in assessing the total causal effect of Open Data on Cost Saving. According to our model (Figure 1), there are multiple pathways from Open Data to Cost Saving, some are causal, some are not. To estimate the causal effect of interest, we need to make sure that all causal paths are open, and all non-causal paths are closed. Within the DAG representation, two causal pathways can be identified: a direct pathway of Open Data \(\rightarrow\) Cost Saving, representing the direct effect of Open Data on Cost Savings, and an indirect pathway Open Data \(\rightarrow\) Time Saving \(\rightarrow\) Cost Saving, where the effect is indirect and mediated by Time Saving. The direct effect captures the immediate benefits of providing free access to datasets, while the indirect effect, mediated by Time Savings, strengthens the relationship by triggering additional efficiencies that also lead to Cost Savings.
To properly estimate the total causal effect of Open Data on Cost Saving, an empirical model should not control for Time saving. On the contrary, if the model conditions on Time Savings, even implicitly (e.g., by accounting for approaches and tools that optimise and speed up data access and processing), it closes the causal path and introduces biases into the estimation of the total effect (Figure 2).
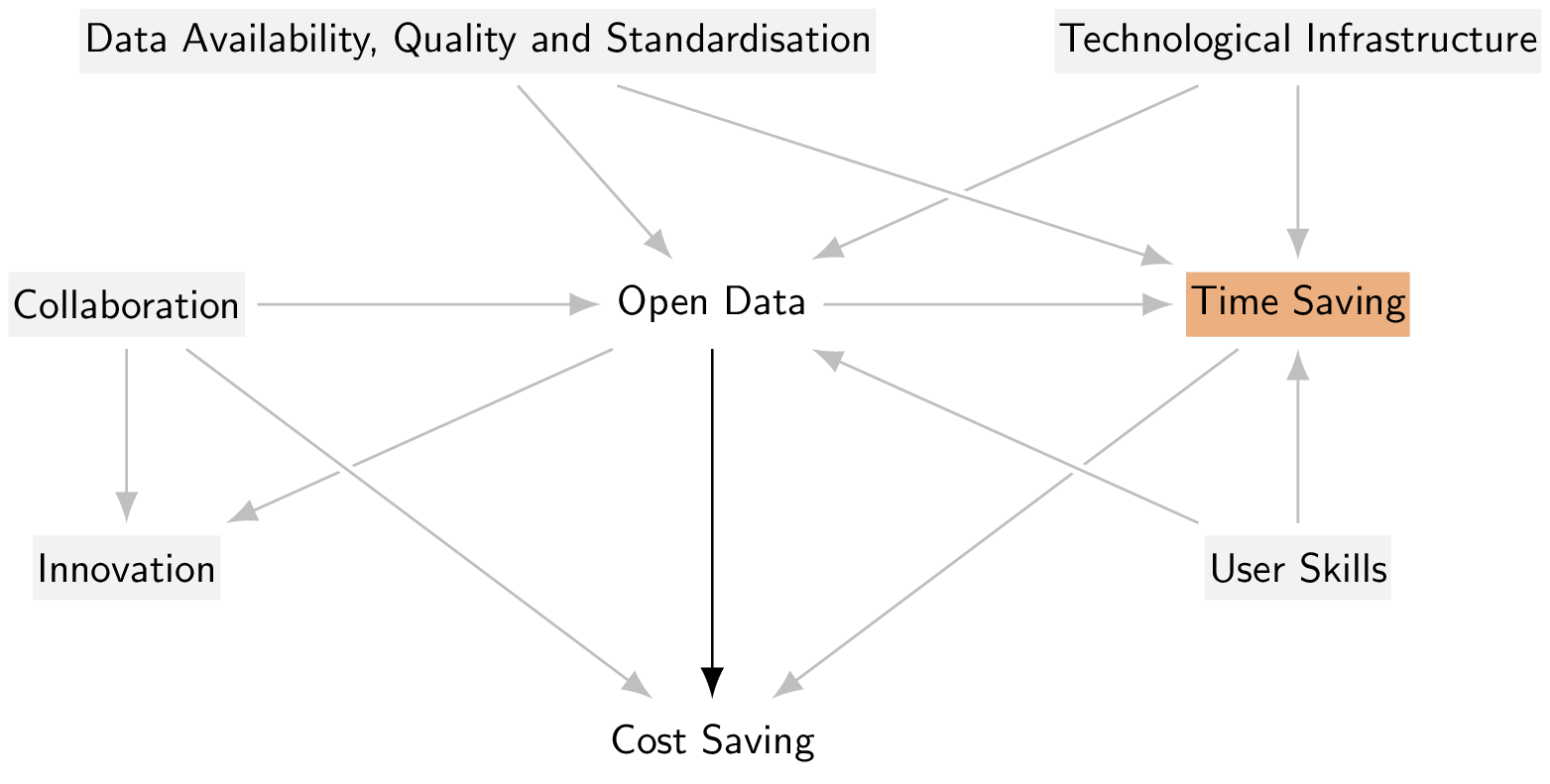
As mentioned before, the proposed model accounts for additional variables such as Data Availability, Quality and Standardisation, Users’ Skills, Collaboration, and Technological Infrastructure. These variables can act as confounders along different pathways illustrated in Figure 1. Examples of non-causal paths represented in the DAG are:
- Open Data \(\leftarrow\) Technological Infrastructure \(\rightarrow\) Time Saving \(\rightarrow\) Cost Saving
- Open Data \(\leftarrow\) Data Availability, Quality and Standardisation \(\rightarrow\) Time Saving \(\rightarrow\) Cost Saving
- Open Data \(\leftarrow\) User’s skills \(\rightarrow\) Time Saving \(\rightarrow\) Cost Saving
In these pathways, to correctly identify the causal effect of Open Data on Time Saving, and by extension, on Cost Savings, it is required to control for these confounders. This is because the confounders jointly affect Open Data and Time Savings and omitting them from empirical models results in omitted variable bias. In the proposed example, to correct identify the causal effect one should control for Technological infrastructure, Data availability, quality and standardisation, and the skills of users.
There might be instances where a confounder is not observed because is not included in the dataset or not observable at all. In such cases, the non-causal path remains open, resulting in biased conclusions. In fact, unobservable factors might be correlated with observable variables, leaving causal paths unexplored. As a result, if these confounders are not accounted for, we are unable to fully isolate the causal effect of Open Data influences Cost saving.
Another case that makes not possible the identification of the causal effect is erroneously controlling for a collider (see the introduction for further details). In the pathway Open Data \(\rightarrow\) Innovation \(\leftarrow\) Collaboration \(\rightarrow\) Cost Saving, the variable Innovation acts as a collider. Hence, this path is already closed, and the bias arises when controlling for innovation.
Empirically speaking, in a model where to estimate the causal effect of Open Data on Cost savings we condition on Innovation (and not for Collaboration), it is likely to get a downward estimation of the causal effect, since both Collaboration and Open Data have a positive impact on Innovation. This conditioning opens up the non-causal pathway, Open Data \(\rightarrow\) Innovation \(\leftarrow\) Collaboration \(\rightarrow\) Cost Saving, which connect Open Data and Cost Saving through Collaboration, creating a spurious association and distorting the true effect of Open Data on Cost Saving. This is an example of bad controls (Angrist and Pischke 2009), a concept explained in the general introduction. Only by ignoring the collider, meaning non-conditioning on it in empirical models, we can effectively isolate the causal effect. This non-causal path is open because Innovation is open (because it is a collider that is conditioned on), and because Collaboration is open (because it is a confounder that is not conditioned on) (see Figure 3).
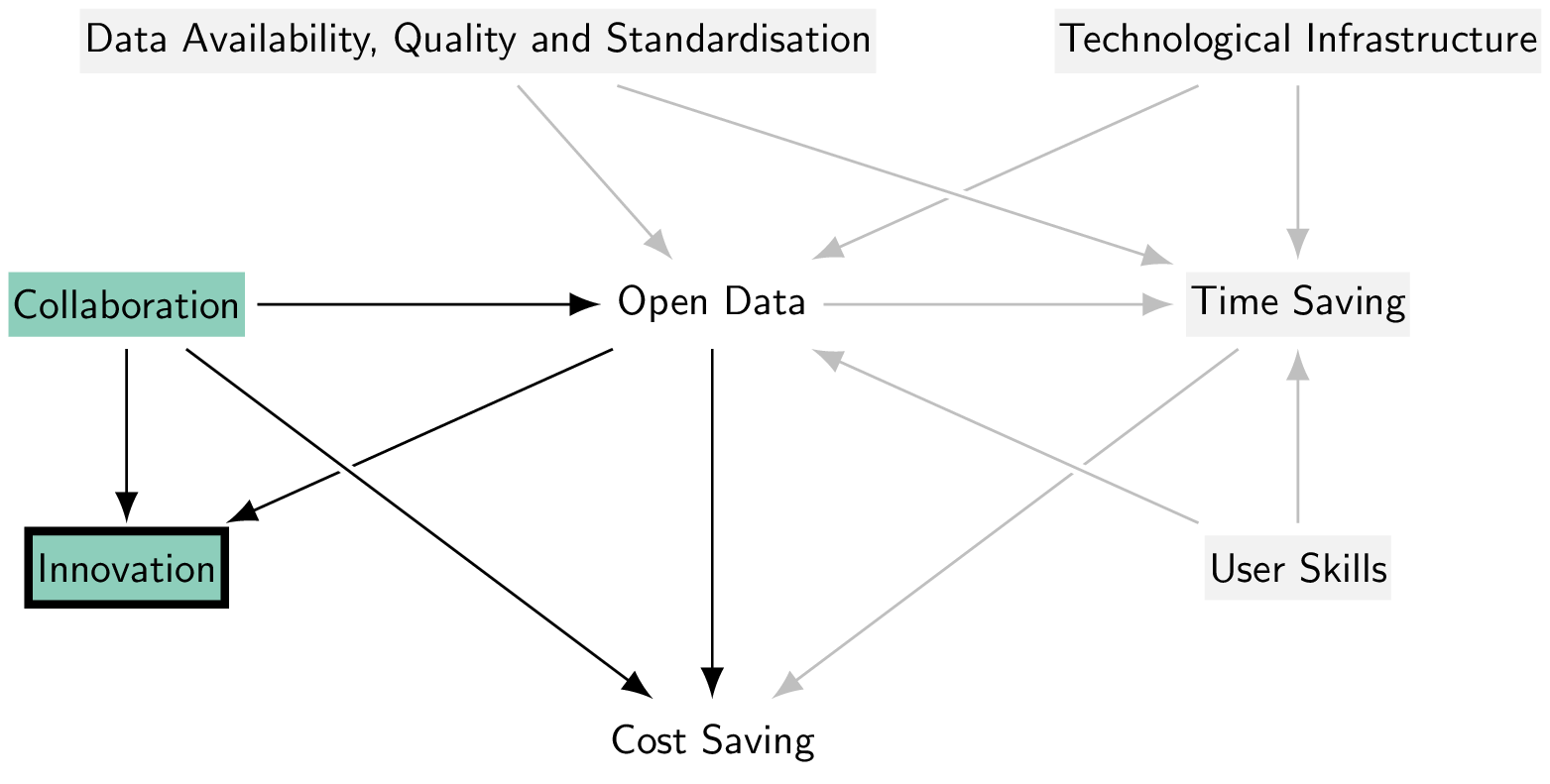
In addition, Collaboration acts as a confounder on the non-causal path Open data \(\leftarrow\) Collaboration \(\rightarrow\) Cost saving. To identify the causal effect, we hence need to close this non-causal path by conditioning on Collaboration. After controlling for Collaboration, whether Innovation is conditioned on is then irrelevant for the identification of the causal effect. When all non-causal paths are closed, the research design is said to meet the backdoor criterion, a formal requirement that ensures the design blocks all non-causal paths between the treatment (Open Data) and the outcome (Cost Saving), enabling us to identify the causal effect in question (Cunningham 2021) (Figure 4).
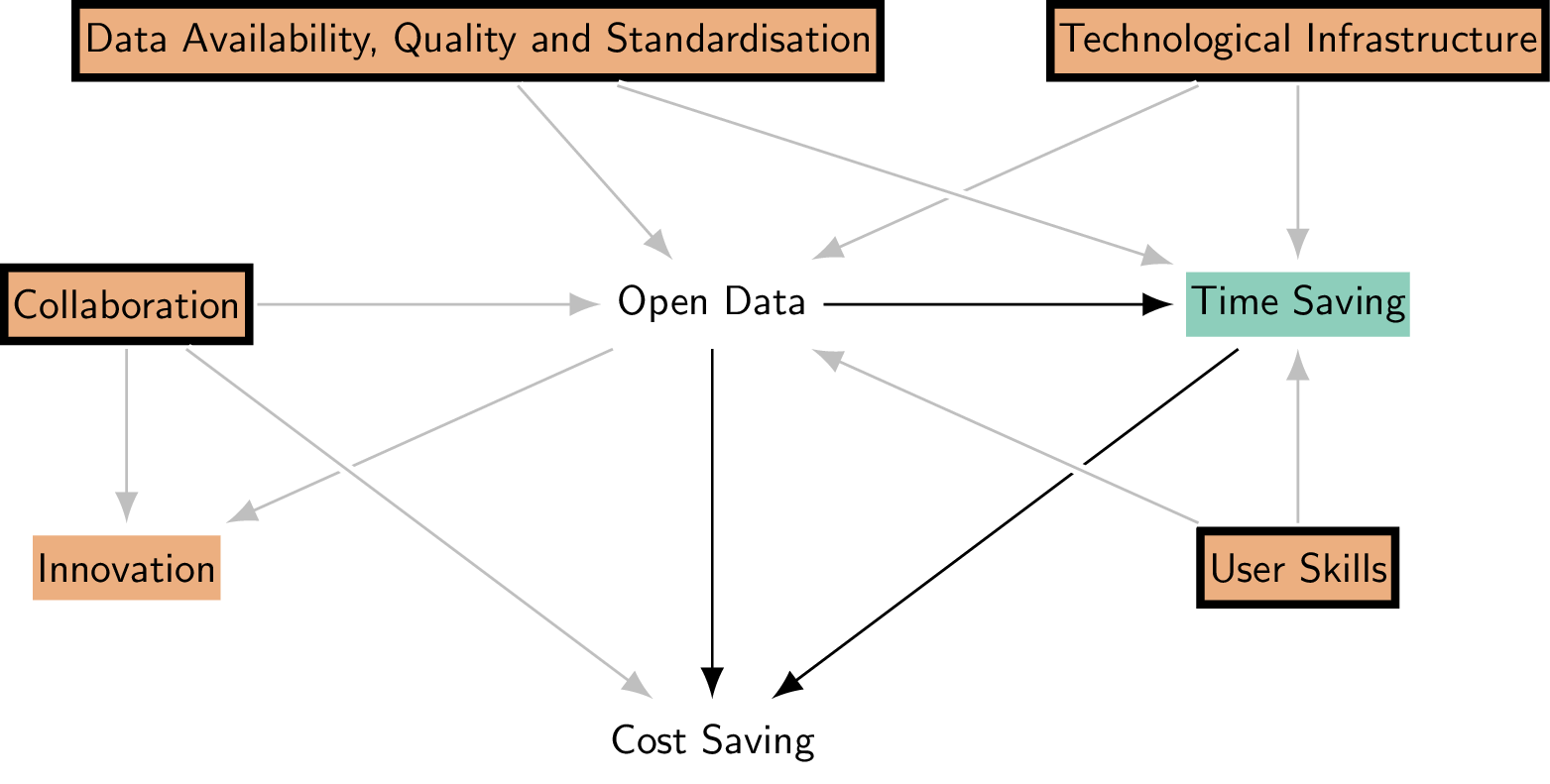
This example highlights key components of causal inference: controlling for confounders (Data availability, quality and standardisation, User skills, Collaboration, and Technological Infrastructure), not controlling for mediators (Time saving), and not controlling for colliders (Innovation), as shown in Figure 4. Constructing an appropriate DAG is important when aiming to draw causal conclusions. Without making assumptions explicit via a DAG, it would be unclear which variables should be controlled for and which not. Omitting important variables weakens the study’s ability to draw accurate conclusions about cause and effect. Moreover, adding complexity to a DAG does not always change the variables that need to be controlled for when identifying the causal effect. In some cases, such as when adding confounders between unrelated variables, the identification of the relationship between Open data and Cost savings remains unaffected. However, if a confounder is introduced between Open data and Cost savings directly, it becomes necessary to control for it.
In the causality introduction we emphasise the importance of carefully selecting variables when analysing causal relationships. The introduction warns against two common errors: relying on the data (e.g., through stepwise regression) to decide which variables to control for, or including all available variables, which McElreath (2020) refers to as “causal salad”. Both approaches can lead to incorrect conclusions. Specifically, including mediating variables or focusing only on certain cases could obscure the true effect of open data on outcomes like cost savings. In this regard, Pearl (2009) proposes using the do-operator1 to define causal effects, where an intervention on one variable allows us to observe changes in another, thereby illuminating causal connections within a system.
This approach is effective in predicting how probability distributions shift under controlled changes when the causal structure is known. However, this approach depends on having an established causal graph, limiting its use for exploring causality from scratch. Critics suggest an alternative approach that allows causal discovery through experimentation without prior assumptions about mechanisms (Woodward 2003). This is especially useful in complex fields, such as social and biomedical sciences, where causal relationships are less understood. Considering this, Cunningham (2021) argues that sample selection problems have been recognised long before the introduction of DAGs, with early solutions like Heckman (1979), and emphasizes that an atheoretical approach to empiricism is inadequate. He asserts that causal inference requires a deep understanding of the behavioural processes behind the phenomenon being studied, and while DAGs are useful, they cannot replace the need for theoretical knowledge in creating credible identification strategies. Thus, causal inference is not solved by simply collecting more data, but by integrating theory with empirical analysis.
Discussing empirical issues
The presented model illustrates how open data might drive cost savings by focusing on a limited set of variables commonly discussed in the literature. However, this approach presents challenges, as the existing literature reveals a significant gap in empirical studies that specifically measure the economic impact of open data on cost savings.
Other relevant factors could be included based on additional evidence but are currently excluded to maintain a coherent link with existing empirical findings and to preserve simplicity. While there is general agreement on the potential benefits of open data for cost savings, no study to date has estimated the total effect using a causal identification strategy such as the one presented here. Moreover, the specific causal pathways remain unclear, as little attention has been paid to the intermediate factors influencing the total effect. This lack of empirical evidence on these pathways limits the ability to draw strong conclusions from the model and underscores the need for more focused empirical research.
It is also important to acknowledge that causal pathways are not static and may evolve depending on the context or field of application. Cunningham (2021) highlights that causal inference requires a deeper understanding of the underlying processes governing the system being studied. It is not solely about the data but also about the theoretical and contextual knowledge of how behaviours, choices, or events interact to produce stable outcomes. Timing and the evolution of causality play a critical role, as interactions between variables change over time, leading to different outcomes in different contexts. This complexity, arising from reverse causality and cyclical interactions, represents a key limitation of this DAG. The relationships between variables are often more intricate, with the potential for bidirectional influences. For example, when organisations share open data, they enable collaborative efforts that can lead to innovative solutions, such as new products or services. Increased collaboration, in turn, may prompt organisations to adopt more open data practices, creating a bidirectional relationship. This innovation can then lead to cost savings by streamlining processes or reducing redundancies. Conversely, independent cost savings may provide the resources necessary for further investment in innovation, illustrating a cyclical relationship where each factor reinforces the other. This dynamic interplay complicates the one-way causal pathways represented in the DAG. Feedback loops and time-dependent changes are often critical in real-world scenarios, making the DAG an initial framework rather than a definitive model. Further empirical research is essential to refine and validate the relationships it proposes, capturing the complexities and nuances of the interactions between these variables.
A targeted survey could be a viable approach to address the empirical challenges arising from the lack of data and counterfactual evidence in studying the economic impact of open data. This survey should be carefully designed to measure the direct effects of open data on cost savings while accounting for confounding factors. It should aim to answer specific research questions, such as the extent of open data sharing, the perceived efficiency gains from data use, and the direct cost reductions attributed to open data initiatives. The survey would need to collect both longitudinal and cross-sectional data from a diverse sample of organisations that share open data as well as those that do not. This would allow for comparisons of outcomes and the establishment of causal relationships. Key variables to be measured should include the extent of open data sharing, cost reductions, new products or services enabled or accelerated by open data, and changes in collaboration. Questions investigating the perceived causal pathways would also be essential. Incorporating temporal data would provide further insight, enabling a better understanding of causal direction and distinguishing between short-term and long-term effects.
Access to such detailed data would enable the use of causal inference techniques, such as Propensity Score Matching (PSM) or the Difference-in-Differences (DID) estimator, to identify the true impact of open data on cost savings. By addressing current data gaps, this survey could provide the empirical evidence needed to validate and refine the DAG, enhancing our understanding of how open data drives economic outcomes like cost savings. For instance, in the PSM context, a rich dataset would support the development of a more comprehensive DAG, helping to identify variables to include in the matching process (e.g., data availability, technological infrastructure, and user skills) and those to exclude (e.g., time savings and innovation). This approach would strengthen the empirical basis for analysing the causal impact of open data.
References
Footnotes
The do-operator is a notation used in causal inference to denote an intervention in a system. Written as , it represents setting variable to a specific value, simulating the effect of this intervention on other variables in the system while breaking any causal connections that usually determine . This approach allows us to differentiate causation from correlation, estimate causal effects, and answer hypothetical “what-if” scenarios. Through do-calculus, a set of rules introduced by Pearl, interventional distributions involving the do-operator can be converted into observational distributions.↩︎
Reuse
Citation
@online{apartis2024,
author = {Apartis, S. and Catalano, G. and Consiglio, G. and Costas,
R. and Delugas, E. and Dulong de Rosnay, M. and Grypari, I. and
Karasz, I. and Klebel, Thomas and Kormann, E. and Manola, N. and
Papageorgiou, H. and Seminaroti, E. and Stavropoulos, P. and Stoy,
L. and Traag, V.A. and van Leeuwen, T. and Venturini, T. and
Vignetti, S. and Waltman, L. and Willemse, T.},
title = {Open {Science} {Impact} {Indicator} {Handbook}},
date = {2024},
url = {https://handbook.pathos-project.eu/sections/0_causality/open_data_cost_savings.html},
doi = {10.5281/zenodo.14538442},
langid = {en}
}